接触sklearn很久了,众所周知,sklearn包含了很多机器学习的方法,可以用几行代码实现丰富的机器学习过程.
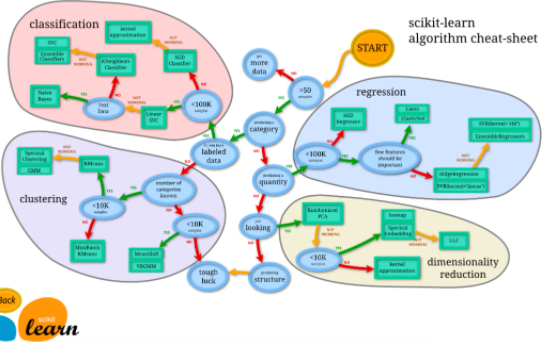 sklearn提供的一些机器学习方法
sklearn提供的一些机器学习方法sklearn.datasets里包含了大量的数据模板,比如大家熟悉的鸢尾花数据集,波士顿房价数据等.
今天要介绍的,是sklearn的另外一个神器功能–生成随机数据.
在学习机器学习的过程中,经常会要用到各种随机数据.sklearn提供了多种多样的随机数据集生成功能.
首先我们导入matplotlib包,方便对数据进行可视化
import matplotlib.pyplot as plt回归模型随机数据
#make_regression生成回归模型数据
from sklearn.datasets import make_regression
#关键参数有n_samples(生成样本数),n_features(样本特征数),noise(样本随机噪音)和coef(是否返回回归系数
# X为样本特征,y为样本输出, coef为回归系数,共1000个样本,每个样本1个特征
X,y,coef=make_regression(n_samples=1000,n_features=1,noise=10,coef=True)
plt.scatter(X,y,c='b',s=3)
plt.plot(X,X*coef,c='r')
plt.xticks(()) #不显示 x
plt.yticks(()) #不显示 y
plt.show()可以方便地设置一些参数,比如样本个数,特征数目,噪音数量(数据离散程度)等参数.
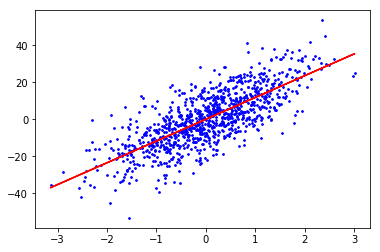 noise=10
noise=10我们改变一下noise的值,调整一下数据的离散程度.
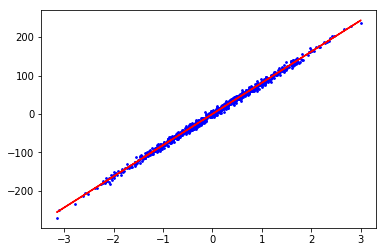 noise=5
noise=5分类模型随机数据
#make_classification生成三元分类模型数据
from sklearn.datasets import make_classification
#关键参数有n_samples(生成样本数), n_features(样本特征数), n_redundant(冗余特征数)和n_classes(输出的类别数)
# X1为样本特征,Y1为样本类别输出, 共400个样本,每个样本2个特征,输出有3个类别,没有冗余特征,每个类别一个簇
X1,Y1=make_classification(n_samples=400,n_features=2,n_redundant=0,n_clusters_per_class=1,n_classes=3)
plt.scatter(X1[:,0],X1[:,1],c=Y1,s=3,marker='o')
plt.show()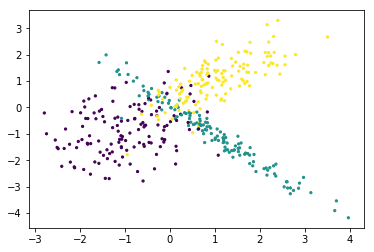
聚类模型随机数据
#make_blobs生成聚类模型数据
from sklearn.datasets import make_blobs
#关键参数有n_samples(生成样本数), n_features(样本特征数),centers(簇中心的个数或者自定义的簇中心)和cluster_std(簇数据方差,代表簇的聚合程度)
# X为样本特征,Y为样本簇类别, 共1000个样本,每个样本2个特征,共3个簇,簇中心在[-1,-1], [1,1], [2,2], 簇方差分别为[0.4, 0.5, 0.2]
X,y=make_blobs(n_samples=1000,n_features=2,centers=[[-1,-1],[1,1],[2,2]],cluster_std=[0.4,0.5,0.2])
plt.scatter(X[:,0],X[:,1],c=y,s=3,marker='o')
plt.show()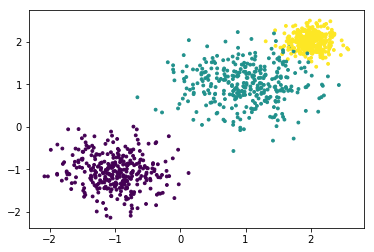
分组正态分布混合数据
#make_gaussian_quantiles生成分组多维正态分布的数据
from sklearn.datasets import make_gaussian_quantiles
#关键参数有n_samples(生成样本数), n_features(正态分布的维数),mean(特征均值), cov(样本协方差的系数), n_classes(数据在正态分布中按分位数分配的组数)
#生成2维正态分布,生成的数据按分位数分成3组,1000个样本,2个样本特征均值为1和2,协方差系数为2
X1,Y1=make_gaussian_quantiles(n_samples=1000,n_features=2,n_classes=3,mean=[1,2],cov=2)
plt.scatter(X1[:,0],X1[:,1],marker='o',c=Y1,s=3)
plt.show()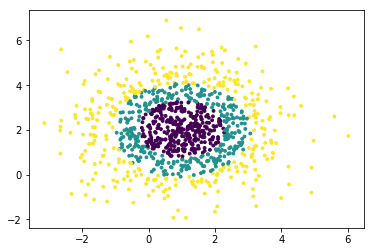 class=3
class=3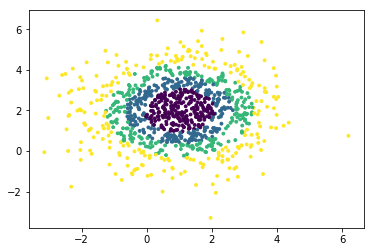 class=4
class=4每一位机器学习爱好者都是一个炼丹术士,计算机是丹炉,数据就像是用于炼丹的各种原材料,相信有了这么方便的工具,在掌握机器学习方法的道路上,可以节约很多时间,让精力专注于机器学习方法本身上来.
 炼丹术士
炼丹术士
发表回复