sklearn是一个功能非常强大的工具,可以用几行代码实现丰富的机器学习算法。
本文介绍使用sklearn实现决策树
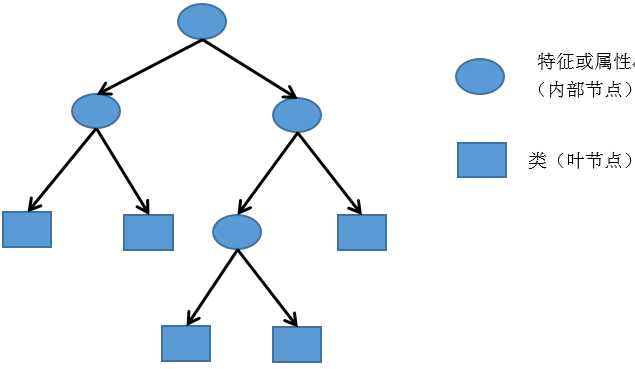
决策树是经典的机器学习算法,很多复杂的机器学习算法都是由决策时演变而来.它是一种使用if-then-else的决策规则的监督学习方法.很容易理解,掌握.
决策树的优点:
- 便于理解和解释。树的结构可以可视化出来。
- 训练需要的数据少。其他机器学习模型通常需要数据规范化,比如构建虚拟变量和移除缺失值,不过请注意,这种模型不支持缺失值。
- 由于训练决策树的数据点的数量导致了决策树的使用开销呈指数分布(训练树模型的时间复杂度是参与训练数据点的对数值)。
- 能够处理数值型数据和分类数据。其他的技术通常只能用来专门分析某一种变量类型的数据集。详情请参阅算法。
- 能够处理多路输出的问题。
- 使用白盒模型。如果某种给定的情况在该模型中是可以观察的,那么就可以轻易的通过布尔逻辑来解释这种情况。相比之下,在黑盒模型中的结果就是很难说明清 楚地。
- 可以通过数值统计测试来验证该模型。这对事解释验证该模型的可靠性成为可能。
- 即使该模型假设的结果与真实模型所提供的数据有些违反,其表现依旧良好。
决策树的缺点:
- 决策树模型容易产生一个过于复杂的模型,这样的模型对数据的泛化性能会很差。这就是所谓的过拟合.一些策略像剪枝、设置叶节点所需的最小样本数或设置数的最大深度是避免出现 该问题最为有效地方法
- 决策树可能是不稳定的,因为数据中的微小变化可能会导致完全不同的树生成。这个问题可以通过决策树的集成来得到缓解
- 在多方面性能最优和简单化概念的要求下,学习一棵最优决策树通常是一个NP难问题。因此,实际的决策树学习算法是基于启发式算法,例如在每个节点进 行局部最优决策的贪心算法。这样的算法不能保证返回全局最优决策树。这个问题可以通过集成学习来训练多棵决策树来缓解,这多棵决策树一般通过对特征和样本有放回的随机采样来生成
- 有些概念很难被决策树学习到,因为决策树很难清楚的表述这些概念。例如XOR,奇偶或者复用器的问题
- 如果某些类在问题中占主导地位会使得创建的决策树有偏差。因此,我们建议在拟合前先对数据集进行平衡
以下代码描述了用sklearn实现决策树分类预测
from sklearn import tree
X = [[0, 0], [1, 1]]
Y = [0, 1]
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, Y)我们将clf打印出来,看一下clf是个什么东西

可以看出来,clf里面包含了很多的决策树参数,这里不详细展开阐述,我们输入一个样本进行简单的预测

基于上面的分类方法,我们使用sklearn使用更多的参数实现完整的决策树。
对于决策树而言,常见的决策树分支方式一共有三种,前两种是基于信息熵的,ID3(信息增益),C4.5(信息增益比),以及基于基尼系数的CART决策树
但是因为到目前为止,sklearn中只实现了ID3与CART决策树,所以我们暂时只能使用这两种决策树,分支方式由超参数criterion决定:
- gini:默认参数,基于基尼系数
- entropy: 基于信息熵,也就是我们的ID3
我们使用鸢尾花数据集来实现决策树,我们这里选择的是gini系数来构建决策树
# 加载数据
from sklearn import datasets,model_selection
def load_data():
iris=datasets.load_iris() # scikit-learn 自带的 iris 数据集
X_train=iris.data
y_train=iris.target
return model_selection.train_test_split(X_train, y_train,test_size=0.25,random_state=0,stratify=y_train)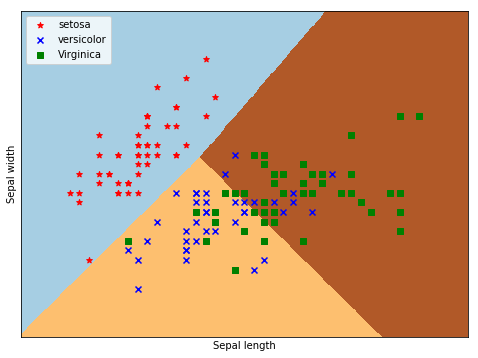 这里我们对鸢尾花数据集进行可视化,图片中已经使用逻辑回归对数据集进行分类(注意:鸢尾花数据集有4个特征,这里只使用了前两个特征)
这里我们对鸢尾花数据集进行可视化,图片中已经使用逻辑回归对数据集进行分类(注意:鸢尾花数据集有4个特征,这里只使用了前两个特征)maxdepth = 40
X_train,X_test,y_train,y_test=load_data()
depths=np.arange(1,maxdepth)
training_scores=[]
testing_scores=[]
for depth in depths:
clf = DecisionTreeClassifier(max_depth=depth)
clf.fit(X_train, y_train)
training_scores.append(clf.score(X_train,y_train))
testing_scores.append(clf.score(X_test,y_test))将结果画出来
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(depths,training_scores,label="traing score",marker='o')
ax.plot(depths,testing_scores,label="testing score",marker='*')
ax.set_xlabel("maxdepth")
ax.set_ylabel("score")
ax.set_title("Decision Tree Classification")
ax.legend(framealpha=0.5,loc='best')
plt.show()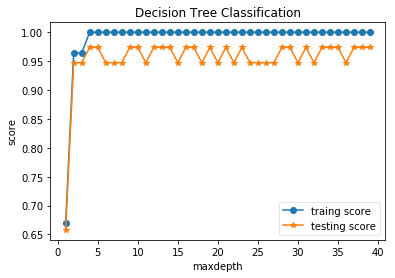
通过上图可以看到,训练集的误差大约在决策树达到5层的时候就达到了0,随着决策树的层数增加,训练集的误差一直不变,但测试集的误差却一直在震荡。这是因为决策树层数过多,导致模型过拟合了.
因此我们需要减掉过多的分支,从而提高决策树的泛化能力.其中的方法虽然很多,但是整体而言都是围绕着枝节点与叶节点展开的
我们还可以将决策树画出来,这里推荐绘制流程图的神器graphviz,这里为了方便画图,重新使用了一段程序.
from sklearn.datasets import load_iris
from sklearn import tree
import graphviz
iris = load_iris()
clf = tree.DecisionTreeClassifier()
clf = clf.fit(iris.data, iris.target)
dot_data = tree.export_graphviz(clf, out_file=None)
graph = graphviz.Source(dot_data)
graph.render("iris")
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)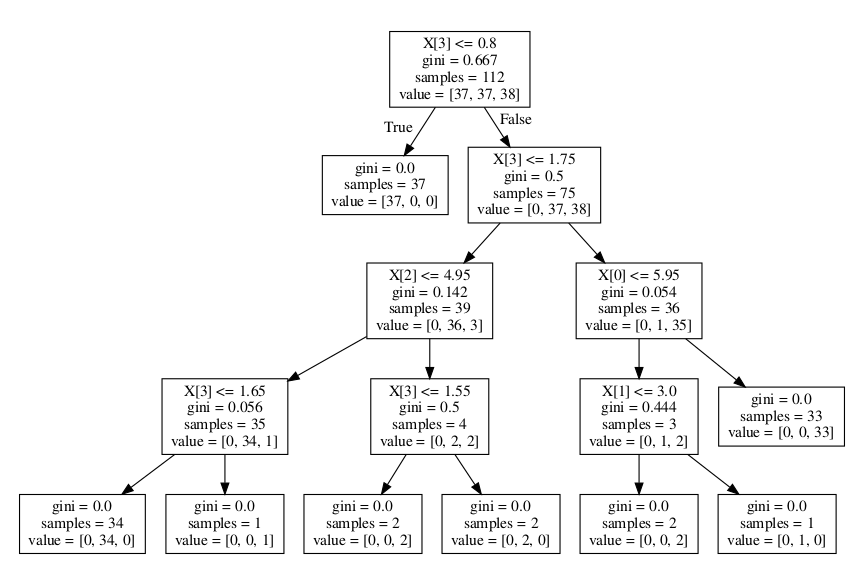 使用gini系数描绘出来的决策树
使用gini系数描绘出来的决策树在sklearn中我们可以用来提高决策树泛化能力的超参数主要有:
- max_depth:树的最大深度,也就是说当树的深度到达max_depth的时候无论还有多少可以分支的特征,决策树都会停止运算.
- min_samples_split: 分裂所需的最小数量的节点数.当叶节点的样本数量小于该参数后,则不再生成分支.该分支的标签分类以该分支下标签最多的类别为准
- min_samples_leaf; 一个分支所需要的最少样本数,如果在分支之后,某一个新增叶节点的特征样本数小于该超参数,则退回,不再进行剪枝.退回后的叶节点的标签以该叶节点中最多的标签你为准
- min_weight_fraction_leaf: 最小的权重系数
- max_leaf_nodes:最大叶节点数,None时无限制,取整数时,忽略max_depth
参考资料:
- sklearn官方文档
- Graphviz安装及简单使用
- 李航<统计学习方法>
发表回复