从硬件来分析,CPU和GPU似乎很像,都有内存、cache、ALU、CU,都有着很多的核心,但是二者是有区别的。
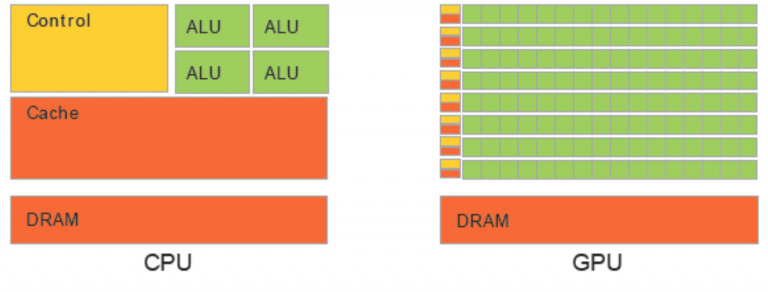 GPU与CPU结构缩略图
GPU与CPU结构缩略图以核心为例,CPU的核心比较重,可以用来处理非常复杂的控制逻辑,预测分支、乱序执行、多级流水等等CPU做得非常好,这样对串行程序的优化做得非常好。

但是GPU的核心就是比较轻,用于优化具有简单控制逻辑的数据并行任务,注重并行程序的吞吐量。

简单来说就是CPU的核心擅长完成多重复杂任务,重在逻辑,重在串行程序;GPU的核心擅长完成具有简单的控制逻辑的任务,重在计算,重在并行。

有一个比较形象的比喻,CPU就像是一个博士,适合处理非常复杂的任务,而GPU就像是一群的小学生,适合处理大量的简单任务(比如加减乘除)。让一名博士去处理大量的加减乘除,速度不一定有大量的小学生同时计算加减乘除来得快
刚好我手里同时有GPU和CPU,能不能做个实验来验证一下,GPU和CPU到底是哪个的运算能力更强大。


我的GPU和CPU:
- GPU:GeForce GTX 1070 TI
- CPU:Intel i5-8500
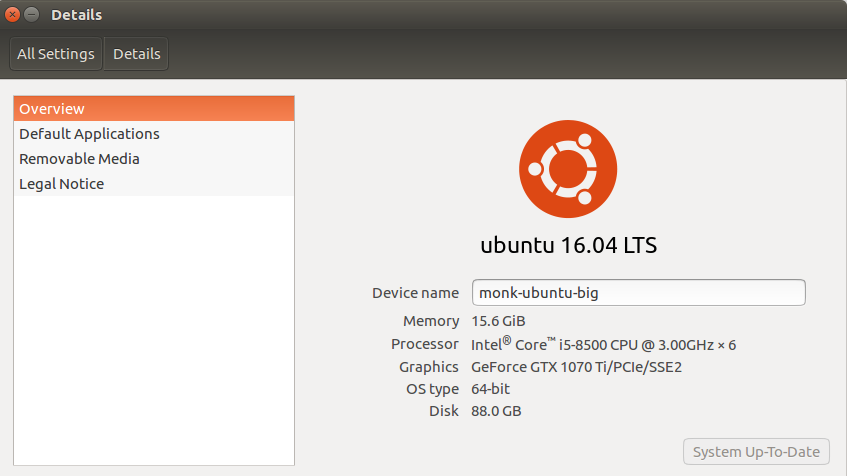 GPU与CPU型号
GPU与CPU型号本次实验在Ubuntu 16.04系统下运行,机器内存16GB DDR4 2666

说干就干,但是,如何评估CPU与GPU算力?
将同一个计算任务同时丢给GPU和CPU进行运算,对比两个处理器处理相同任务所耗费时间的差异。
我选择了计算矩阵的逆作为评估标准,主要原因有以下几点:
- 矩阵的逆非常消耗计算资源
- 写代码实现矩阵的逆很容易
- 可以随意选择矩阵的维度与矩阵的行列数,控制计算任务的难度
我已经预装了tensorflow-gpu版本,以下代码用GPU计算矩阵的逆。
# n表示矩阵的行列数
mat_tf = tf.random_normal((n, n), 0, 1)
mat_tf_inv = tf.matrix_inverse(mat_tf) TensorFlow
TensorFlow使用Python的numpy包来表示CPU模式下对矩阵进行求逆
# n表示矩阵的行列数
mat_normal = np.mat(np.random.normal(0, 1, (n, n)))
mat_normal_inv = np.linalg.inv(mat_normal)
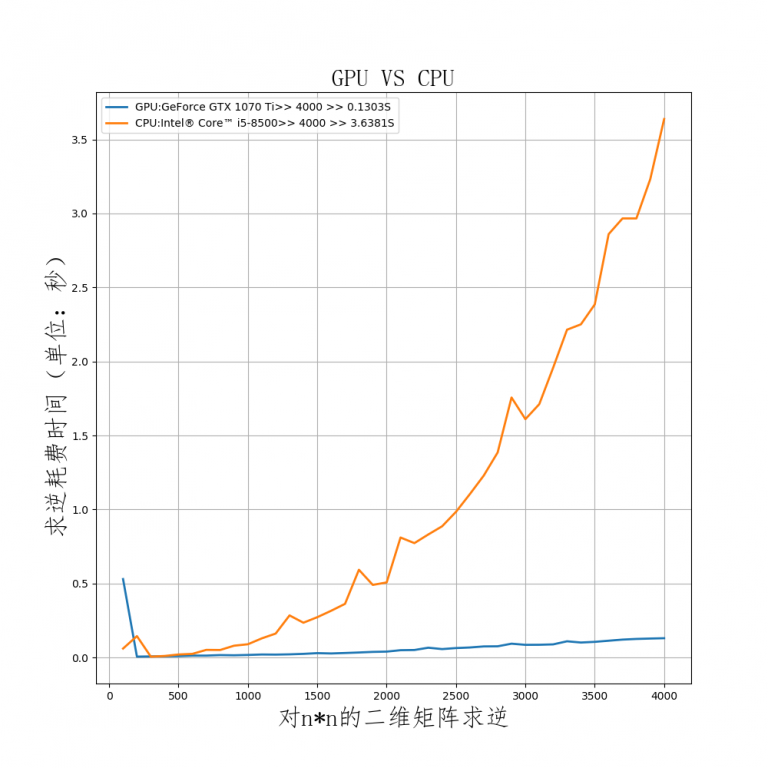
使用上面的代码对n从0到10000进行了计算,并计算了每一个n值条件下,CPU与GPU所花费的时间。
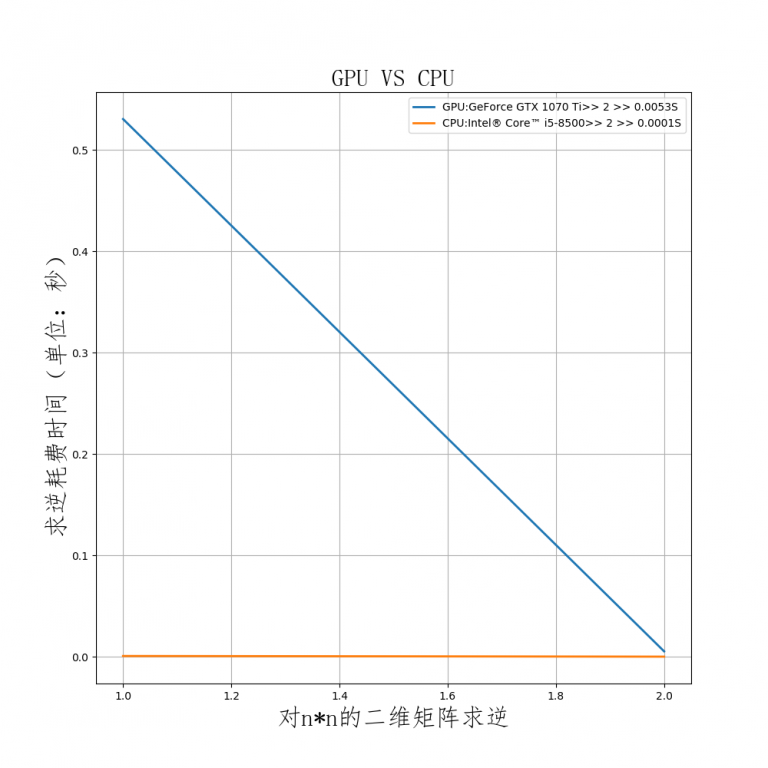
一开始,GPU花的时间比CPU多很多
计算2*2的二维矩阵的逆GPU用时0.0053s,cpu用时0.0001s,GPU用时是CPU的53倍。(这里的时间值保留小数点后位数字,实际上gpu所花时间为0.0052776336669921875,cpu所花时间为7.176399230957031e-05)
但很快地,随着计算量的增加GPU所花费的时间和CPU相差无几,当矩阵的行列数增加到400时,GPU与CPU计算所花费的时间相差无几,gpu所花时间为0.00,85s,cpu所花时间为0.0104s
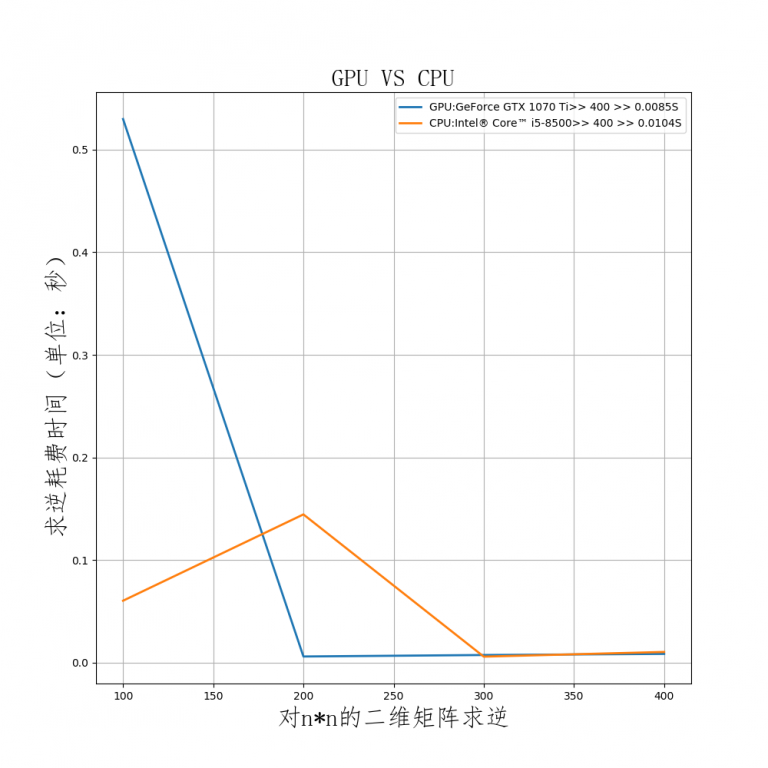
随着计算量的不断增加,GPU所花费的时间增长呈现线性规律,而CPU所花费的时间曲线存在一些毛刺(可能是因为CPU同时在运行其他程序,容易受到影响)。
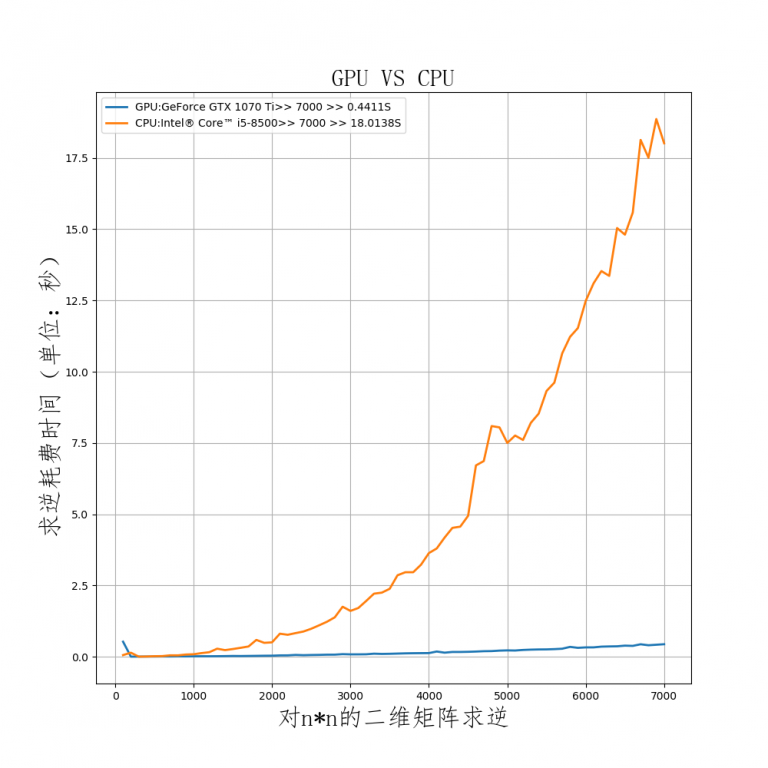
当矩阵行列值增加到7000时,可以看出,GPU所花时间的增长缓慢,而CPU的时间曲线则越来越陡峭。此时CPU与GPU消耗时间的比例为40倍!
n继续增加,当n加大到10000时,gpu所花时间为1.0294s,cpu所花时间为52.6677s,CPU花费的时间大约是GPU的50倍!
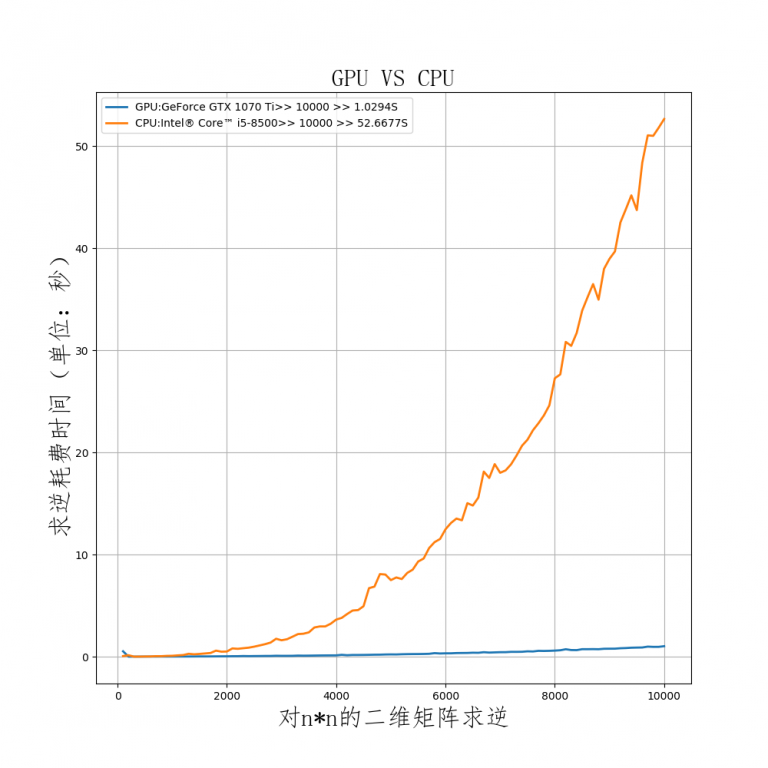 当n增加到10000时,CPU花费的时间大约是GPU的50倍
当n增加到10000时,CPU花费的时间大约是GPU的50倍GPU的处理速度之快得益于它可以高效地处理矩阵乘法和卷积,有一块好的GPU能极大地加大计算速度。

CPU与GPU就像法拉利与卡车,两者的任务都是从随机位置A提取货物(即数据包),并将这些货物传送到另一个随机位置B,法拉利(CPU)可以快速地从RAM里获取一些货物,而大卡车(GPU)则慢很多,有着更高的延迟。但是,法拉利传送完所有货物需要往返多次:
相比之下,大卡车虽然起步没有法拉利快,但它可以一次提取更多的货物,减少往返次数:
最好的CPU大约能达到50GB/s的内存带宽,而最好的GPU能达到750GB/s的内存带宽。因此,在内存方面,计算操作越复杂,GPU对CPU的优势就越明显。
如果把机器学习的成果比作仙丹,那么,用于训练模型的计算机就是丹炉。显然,好的丹炉是可以缩短模型训练的时间从而节约炼丹者(机器学习爱好者)的生命的。
 机器学习爱好者就像是炼丹术士,将数据用一定的配方扔进丹炉,等待一定时间,炼出仙丹。
机器学习爱好者就像是炼丹术士,将数据用一定的配方扔进丹炉,等待一定时间,炼出仙丹。
发表回复