爬虫经常面临的一个需求就是数据输出,在刚开始接触爬虫的时候,我通常都是将数据整理好后,写入txt,csv或者excel中.
后来我接触了数据库,比之前将数据写入文件中方便太多,而且更加易于管理,我总结了使用数据库进行存储的几个优点
- 数据库包含的主键冲突机制可以避免重复地写入数据.
- 可以使用增删查改逻辑来操作数据,可以更方便定制规则抽取数据
- 可以更快地进行读写操作(在大规模多线程爬虫的情况下,这个优势就体现出来了)
- python有很多包可以操作多种数据库

很长一段时间,我都是使用MySQL存储管理我的爬虫数据,直到后来,我接触到了mongodb.
一瞬间,我就被mongodb这种非关系型数据库给吸引了,要知道,在使用MySQL的时候,爬虫一开始就需要考虑建表,还经常面临字段长度溢出,需求改变,时刻需要关注表结构是否需要修改等等一堆问题.

使用mongodb,更本没有这些烦烦恼,在爬到数据后进行存储,你只需要做两件事情:
- 将数据整理成字典或Json格式
- 使用Python将数据插入mongodb
 你只需要将数据整理成这种形式的格式就可以插入了
你只需要将数据整理成这种形式的格式就可以插入了将字段整理成格式化的字符串一点都不复杂,况且,有大量的爬虫是动态接口爬虫,你向一个接口地址发送请求后,这个接口地址直接向你返回一串Json字符串.
使用mongodb,可以获得这些便利:
- 不需要设置表结构
- 数据插入简单,Python只需要短短几行就可以完成插入
- 没有字段长度要求
- 非关系型数据库,一张表存储所有的数据
- 可以设置index,插入的时候避免重复,减少使用数据时清晰数据的工作量
mongodb这种存储方式,简直就是为了动态接口爬虫而生的好不好!我最近在爬取链家的租房信息,中间的爬虫过程省略了,直接展示操作mongodb的过程.
Python操作mongodb可以使用pymongo这个包,经过简单的配置后,就链接到你的mongo数据库了
你可以定义你的db(类似于MySQL中的数据库database),以及collection(类似于MySQL中的标table)
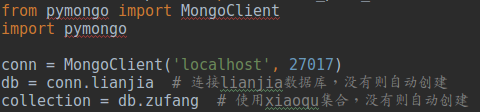 使用Python链接mongoldb数据库
使用Python链接mongoldb数据库对链家的爬虫过程省略了,下图是获得爬虫数据后,将数据整理成字典格式.
这里需要注意,有的网站接口是直接返回了json字符串,更加方便.
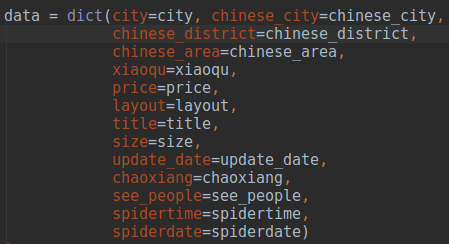 爬虫得到数据后,将数据整理成字典格式
爬虫得到数据后,将数据整理成字典格式将数据插入mongodb中,这里我添加了index,因此添加了异常处理机制.
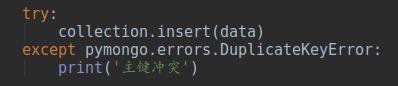 将数据插入mongodb中
将数据插入mongodb中关于Python对mongodb更丰富的操作,可以进行百度.
不论是自己组装的字典还是向接口发送请求直接得到的json字符串,实际上已经是规则的了.将数据保存在mongodb中,可以很容易看到非常规整的数据.
推荐使用IDE–ROBO 3T,这是一款开源免费的软件,非常方便.
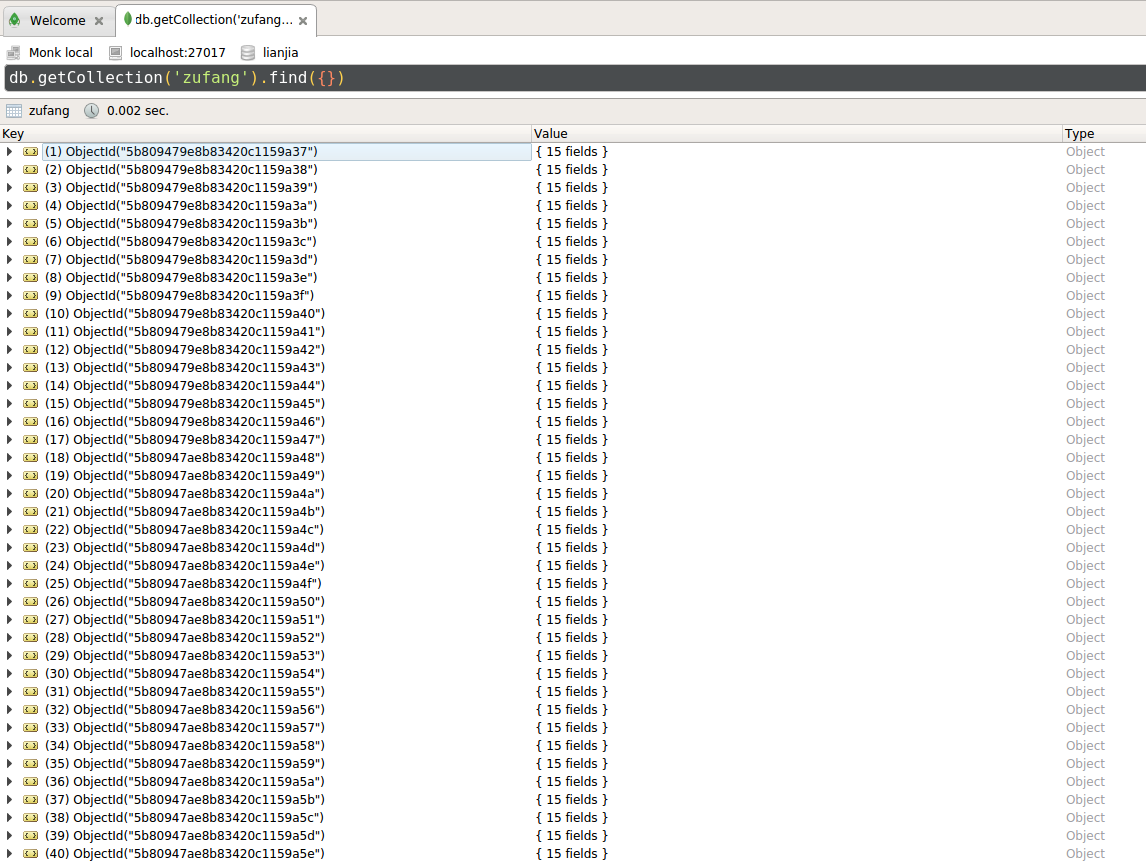 在Mongodb的IDE ROBO 3T中查看存放的数据
在Mongodb的IDE ROBO 3T中查看存放的数据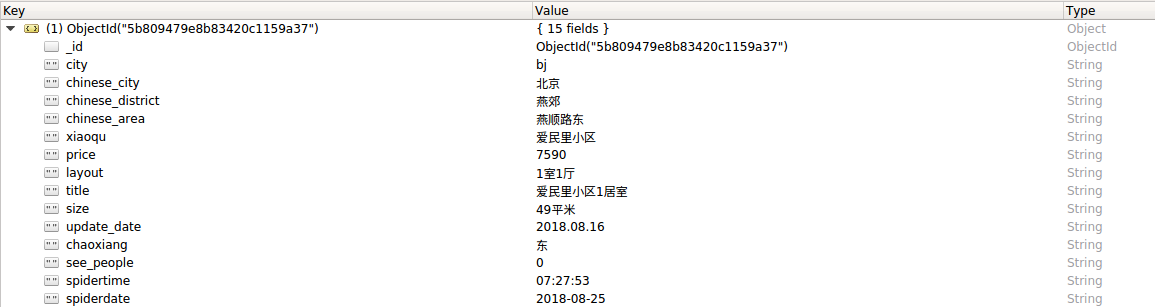 某一条记录的数据
某一条记录的数据
发表回复