在企查查查询企业信息的时候,得到了一些word文件,里面有些控股企业的数据放在表格里,需要我们将其提取出来。
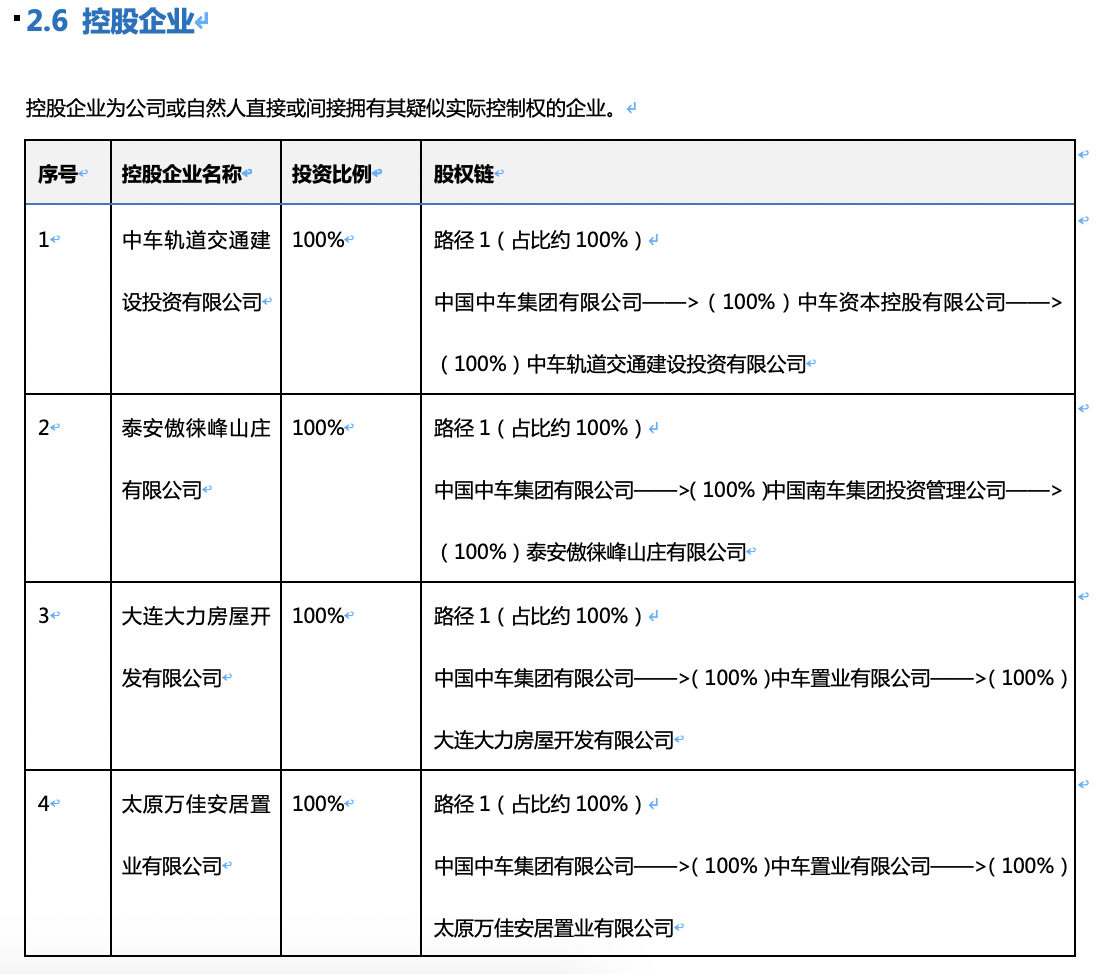
word文件看起来很复杂,不方便进行结构化。实际上,一个word文档中大概有这么几种类型的内容:paragraph(段落),table(表格),character(字符)。我现在要解析的word文档中,基本都是段落和表格,本文主要来讲一下如何从word中解析出表格,并将表格信息进行结构化。
要想使用python解析word文件,我们可以使用包docx,首先我们需要安装它。
pip install python-docx安装完成后,我们需要读取word文件,代码大致如下:
import docx
from docx import Document
docFile = '国家电网有限公司.docx'
document = Document(docFile) #读入文件
tables = document.tables #获取文件中的表格集上面的代码中,tables已经是word文件中所有的table构成的list,我要寻找的表格2.6是word文件中的第9个table,可以这样读取。
table = tables[8]#获取文件中的第9个表格
for i in range(1, len(table.rows)):#从表格第二行开始循环读取表格数据
idNum = table.cell(i,0).text #序号
companyName = table.cell(i,1).text #控股企业名称
investmentRate = table.cell(i,2).text #投资比例
stock= table.cell(i,3).text #股权链
这里已经将表2.6的每一列每一行遍历啦,之后可以将抽取出来的4个参数写到CSV或插入数据库中。


发表回复