机器在学习
gensim在NLP中使用非常方便,几行代码就可以训练处一个词向量,本文记录gensim训练词向量的过程,以及对训练得到的词向量文件进行读取,分析等过程。
以下是使用gensim训练词向量的代码。
from gensim.models import Word2Vecfrom gensim.models.word2vec import LineSentencesentences = LineSentence('wiki.zh.word.text')model = Word2Vec(sentences, size=128, window=5, min_count=5, workers=4)model.save('gensim_128')
简单的几行代码,规定了词向量尺寸,滑窗等参数,就得到了一个词向量文件“gensim_128”,
接下来我们读取这个“gensim_128”词向量文件
from gensim.models import Word2Vecmodel = Word2Vec.load('gensim_128')
得到model后,就可以做一些相关性比较了,gensim已经高度集成,使用起来也非常方便。
from gensim.models import Word2Vecmodel = Word2Vec.load('gensim_128')# 相关词items = model.wv.most_similar('数学')for i, item in enumerate(items): print(i, item[0], item[1])# 语义类比print('=' * 20)items = model.wv.most_similar(positive=['纽约', '中国'], negative=['北京'])for i, item in enumerate(items): print(i, item[0], item[1])# 不相关词print('=' * 20)print(model.wv.doesnt_match(['早餐', '午餐', '晚餐', '手机']))# 计算相关度print('=' * 20)print(model.wv.similarity('男人', '女人'))
这和我想要的还有点不一样,虽然使用起来方便,但是model内部到底有些什么?128维的词向量,到底是什么样子的?我能不能直接获得这些向量,从而编写一些算法做一些特定的处理。
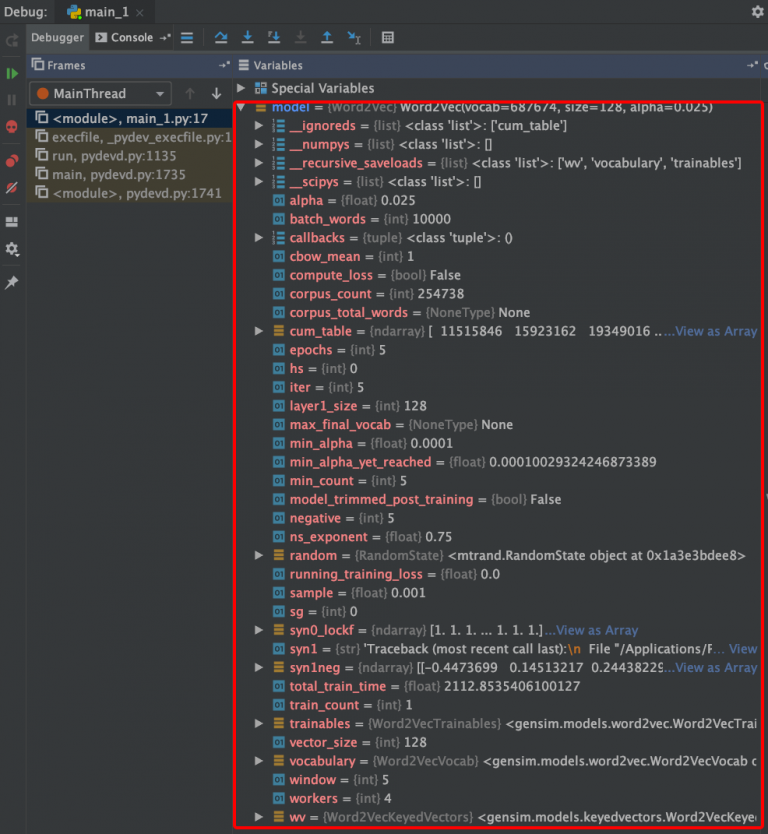
其实,除了查看官方文档,我通常还会用debug模式,查看变量内部到底由什么组成,进而熟悉它的功能,必要的时候,还可以查看源码,更加了解内部的过程。
通过debug查看,可以看到model.wv.index2word对应的是词列表
# 词列表model.wv.index2word
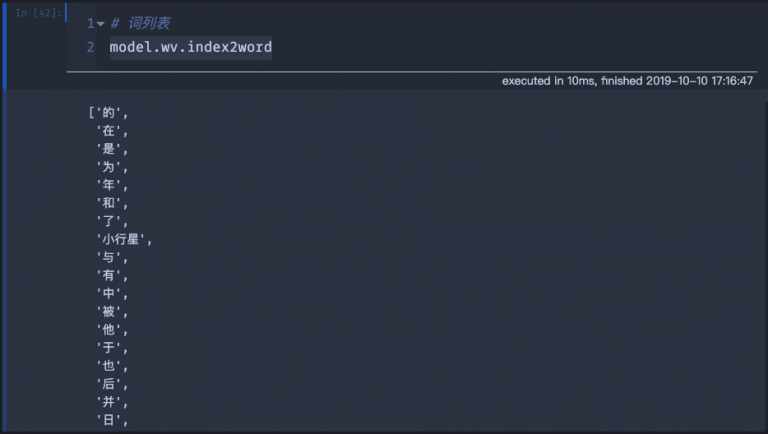
通过debug查看,可以看到model.wv.vectors对应的是词向量
# 词向量print('词向量维度:', model.wv.vectors.shape)print(model.wv.vectors)
词向量是一个(687674, 128)的二维矩阵,这和我们之前训练词向量时,设置的size=128是一致的,而687674是指该词向量模型中,含有687674个不重复的词。
我们已经获取了词向量,词向量对应的单词顺序,和上面model.wv.index2word对应的词列表顺序是一致的。
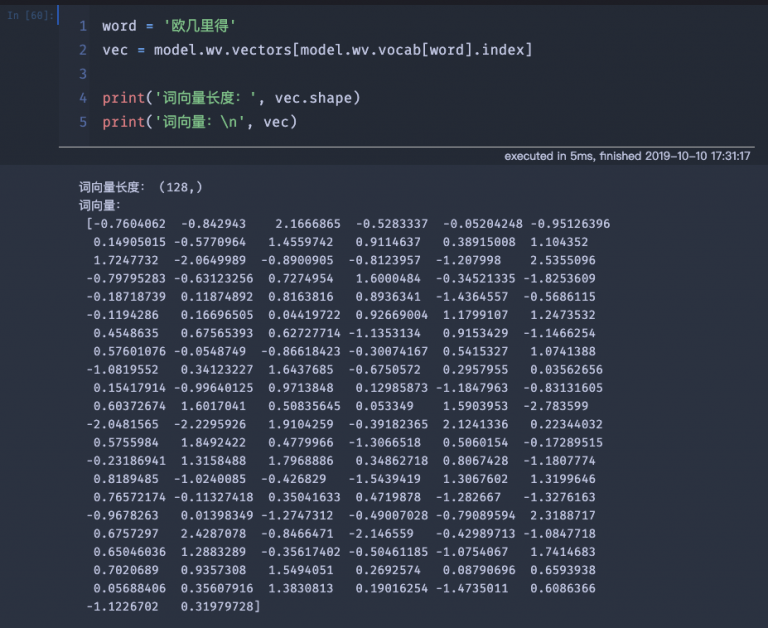
我们可以通过下面的方式,抽取特定单词的词向量。
word = '欧几里得'vec = model.wv.vectors[model.wv.vocab[word].index]print('词向量长度:', vec.shape)print('词向量:\n', vec)
获取了词向量后,就可以编写算法完成后面的过程啦。
有时间再更新~
The End
已发布
分类
标签:
您的电子邮箱地址不会被公开。 必填项已用*标注
评论 *
显示名称
电子邮箱地址
网站地址
Δ

发表回复