当我们采集了一大段声音后,有时候需要将这段声音的每一句话分离开来做分析,本文提供一种方法,可以将大段声音进行有效的切割。
首先,我们写一段代码,读取音频文件,来看一下声音的波形吧。
import matplotlib.pyplot as plt
import soundfile as sf
musicFileName = '你的音频文件名'
sig, sample_rate = sf.read(musicFileName)
print("采样率:%d" % sample_rate)
print("时长:", sig.shape[0]/sample_rate, '秒')
# 声音有两个通道
serviceData = sig.T[0]
clientData = sig.T[1]
plt.rcParams['figure.figsize'] = (20, 5) # 设置figure_size尺寸
plt.figure()
l=sig.shape[0]
x = [i/8000 for i in range(l)]
plt.plot(x, serviceData, c='b')
plt.show()
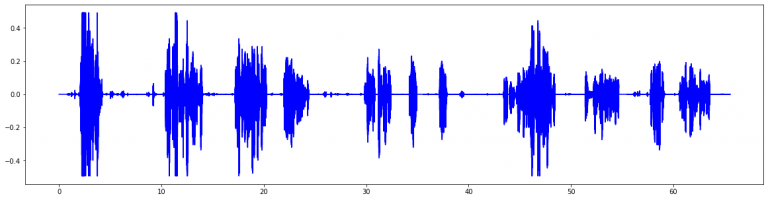
实际上,读取声音文件后,就成为了一个向量,可以看出,声音波形起起伏伏,每句话之间有一定间隙,并且声音的间隙还存在一定噪音。为了完成切割,我设置了三个参数:
- voiceMinValue:最小音量,小于该值即判断为噪音
- voiceMaxDistanceSecond:两句话之间做大时间间隔,大于该值即认为是两句话,否则认为是一句话
- voiceMinSecond:单个音频最小时间长度,小于该值即认为是噪音
上述的三个参数,加上音频文件名称,文件输出路径,构成了类的初始值
class Voicesplit(object):
def __init__(self, musicFileName, outFilePath):
# 音频文件名称
self.musicFileName = musicFileName
# 文件输出路径
self.outFilePath = outFilePath
# 最小音量
self.voiceMinValue = 0.01
# 两句话之间最大时间间隔(秒)
self.voiceMaxDistanceSecond = 0.1
# 单个音频最小时间长度(秒)
self.voiceMinSecond = 0.1
以下代码使用上面的三个关键参数进行切割。
# 分割声音,分段保存
@retry(tries=5, delay=2)
def splitVoiceAndSave(self):
sig, self.sample_rate = sf.read(self.musicFileName)
print('正在读取文件:%s' % musicFileName)
print("采样率:%d" % self.sample_rate)
print("时长:%s" % (sig.shape[0] / self.sample_rate), '秒')
# 我的音频文件有两个通道,这里读取第一个通道,你需要根据你的音频文件是否是双通道,进行修改
inputData = sig.T[0]
dd = {}
for k, v in tqdm(enumerate(inputData)):
if abs(v) < self.voiceMinValue:
dd[k] = 0
else:
dd[k] = v
x = [i / self.sample_rate for i in range(len(inputData))]
y = list(dd.values())
# 删除空白部分
for key in list(dd):
if dd[key] == 0:
dd.pop(key)
# 判断声音间隔
voiceSignalTime = list(dd.keys())
list1 = []
list2 = []
for k, v in enumerate(voiceSignalTime[:-2]):
list2.append(v)
if voiceSignalTime[k + 1] - v > self.voiceMaxDistanceSecond * self.sample_rate:
list1.append(list2)
list2 = []
if len(list1) == 0:
list1.append(list2)
if len(list1) > 0 and (
voiceSignalTime[-1] - voiceSignalTime[-2]) < self.voiceMaxDistanceSecond * self.sample_rate:
list1[-1].append(voiceSignalTime[-2])
voiceTimeList = [x for x in list1 if len(x) > self.voiceMinSecond * self.sample_rate]
print('分解出声音片段:', len(voiceTimeList))
for voiceTime in voiceTimeList:
voiceTime1 = int(max(0, voiceTime[0] - 0.8 * self.sample_rate))
voiceTime2 = int(min(sig.shape[0], voiceTime[-1] + 0.8 * self.sample_rate))
self.wavWriteByTime(musicFileName=self.musicFileName, outData=inputData, voiceTime1=voiceTime1, voiceTime2=voiceTime2)
下面的代码功能是对切割的声音片段进行保存。
# wav文件写入,分时间间隔
def wavWriteByTime(self, musicFileName, outData, voiceTime1, voiceTime2):
outData = outData[voiceTime1:voiceTime2]
fileAbsoluteName = os.path.splitext(os.path.split(musicFileName)[-1])[0]
fileSavePath = os.path.join(self.outFilePath, fileAbsoluteName)
if not os.path.exists(fileSavePath):
os.makedirs(fileSavePath)
outfile = os.path.join(fileSavePath,os.path.splitext(os.path.split(musicFileName)[-1])[0] + '_%d_%d_%s_split.wav' % (voiceTime1, voiceTime2, self.sample_rate))
# 判断文件是否存在
if not os.path.exists(outfile):
print('正在生成文件:', outfile)
with wave.open(outfile, 'wb') as outwave: # 定义存储路径以及文件名
nchannels = 1
sampwidth = 2
fs = 8000
data_size = len(outData)
framerate = int(fs)
nframes = data_size
comptype = "NONE"
compname = "not compressed"
outwave.setparams((nchannels, sampwidth, framerate, nframes, comptype, compname))
for v in outData:
outwave.writeframes(struct.pack('h', int(v * 64000 / 2)))
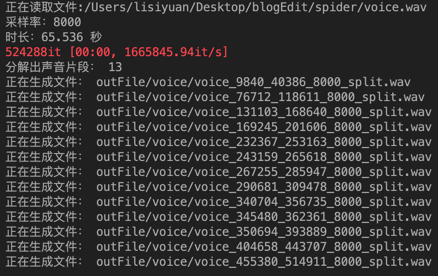
以下是代码运行情况,将声音分割成为了13个片段。
完整代码已上传至github:https://github.com/shulisiyuan/viceSplit

发表回复