IT桔子是关注IT互联网行业的结构化的公司数据库和商业信息服务提供商,里面有很多有用的信息。于是,我又想爬IT桔子?来提升一下我的爬虫技术了。(注意:IT桔子有用户校验机制,没有购买VIP的用户很多信息是看不到的)
我选择爬取IT桔子网站上的公司,爬虫入口地址,一开始爬虫是很顺利的,爬虫的数据放在MongoDB里面
 MongoDB中存放的部分数据
MongoDB中存放的部分数据但是很快,就碰到了IT桔子的反爬虫,一查才知道,原来是自己的ip访问过于频繁,被IT桔子ban了。于是,我购买了一个代理IP池,不停切换IP来运行爬虫,果然顺利了很多。
果然我还是太年轻,以为买了代理ip就解决问题了,很快我再次被ban了,但是通过页面上登录可以正常进入。查一下我找到了原因:我的cookie信息过期了。
我观察了一下爬虫请求的headers。
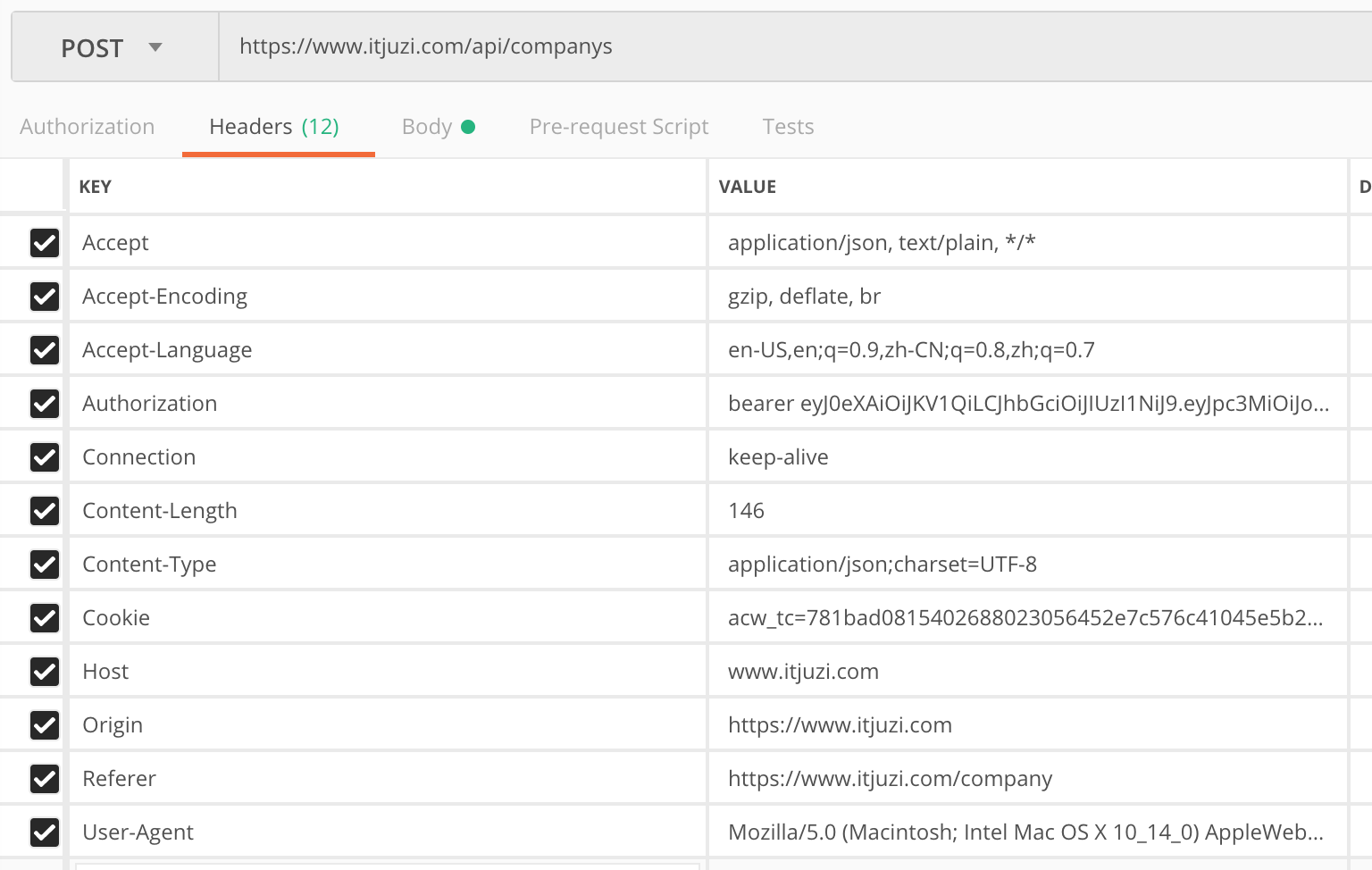
headers里面判断身份是cookie与authorization两个字段,其中cookie字段里面最关键的是acw_tc参数。
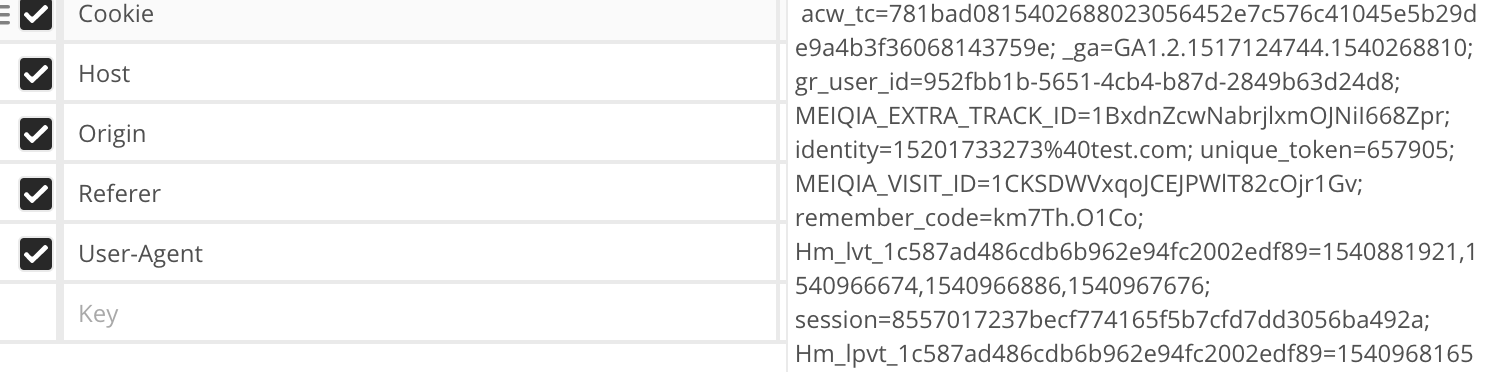
观察发现,acw_tc应该是一个字母与数字组合的随机字符串。并且长度应该是62位,可以直接用Python生成随机的62位字符串得到cookie字段。
拿到cookie后,缺少authorization字段,好像也没有什么用。我试着去登录了一下:IT桔子登录界面入口
启用F12开发者工具抓包
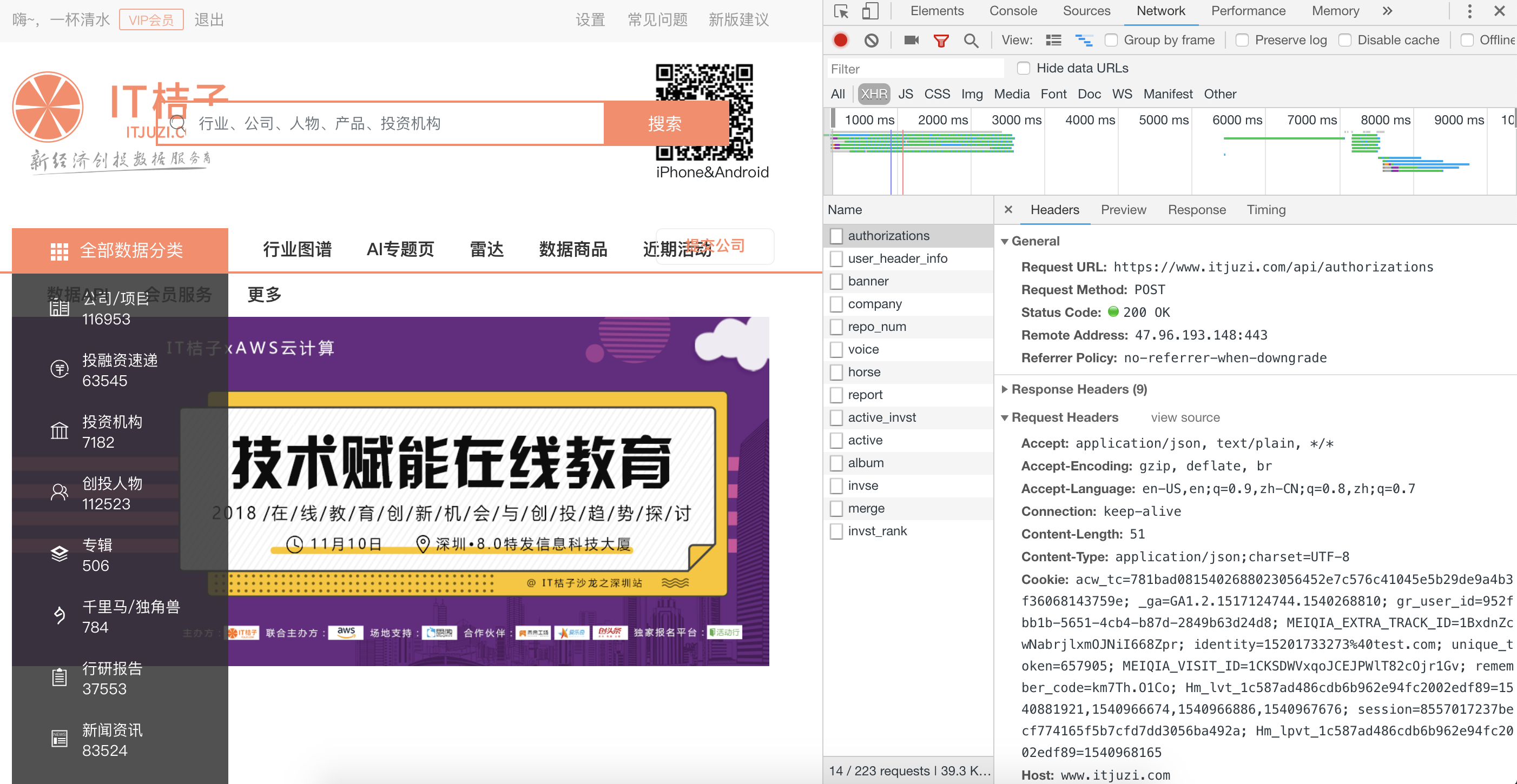 左侧是登录后的页面,右侧是网络请求信息
左侧是登录后的页面,右侧是网络请求信息可以看到一个名为authorization的请求,点进去进行分析,在接口的response里可以看到这些信息。
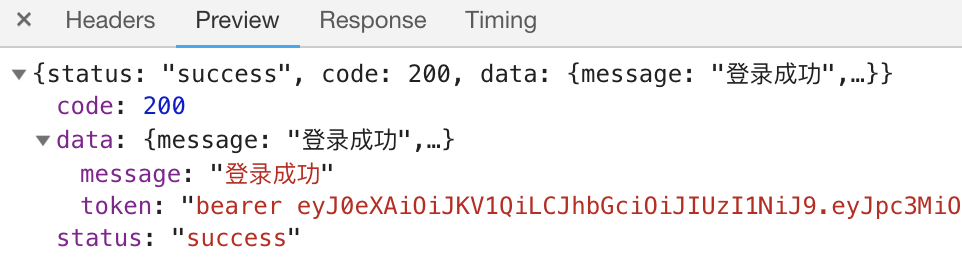 response信息
response信息可以看到,这个接口向我们返回了一个token,这个token的value前面有一个‘bearer’和前面看到的authorization一样,因此初步判断,这个接口应该就是使用cookie中的acw_tc值获得authorization的方法。
拿到cookie与authorization两个参数后,包装成一个headers,再向文章开头的地址发送请求,结果通了,说明我们生产的headers生效了。
这里还是花了一点心思的,但是问题解决的时候也很开心,目前已经可以稳定的爬虫了。
另外,在向身边的安全测试工程师沟通的过程中了解到了一些web安全方面的知识,除了这种方法动态获得headers,还可以把用户名密码放到selenium中,间隔一段时间出发一些点击事件,让后台服务器误以为这个用户一直在浏览,延长账号密码的生命周期。但是这里我没有时间再尝试了,快速拿到数据进行分析对我来说是最重要的。
心得:
- 爬虫过程中遇到的问题,通常不能一次解决掉,总是在过程中不停遇到问题,不停解决。
- 爬虫与反爬虫的斗争,最后一定是爬虫获胜。因为反爬虫再怎么严厉,也一定不会反用户。

发表回复