基于用户的协同过滤算法是推荐系统中最古老的算法,协同过滤,从字面上理解,就是分析用户行为之间的关系,对特定用户进行推荐.
用户行为数据有很多,大概可以分为这么几类:浏览、点击、购买、评分、评论、分享等等。
本文使用MovieLens的1M数据集,这里计算用户相似度只用到了数据ratings.data.
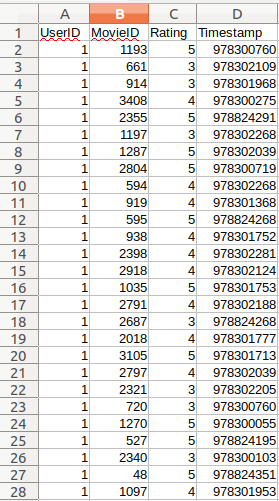 ratings.data中包含userid,以及user对观看过的movie的评分信息与时间
ratings.data中包含userid,以及user对观看过的movie的评分信息与时间为了方便处理,本文已经将user.data转换为user.csv,这份数据集可以点击这里下载
我们使用余弦相似度来计算两个用户观看电影相似度之间的差距的,下面两张图片给出了二维向量余弦相似度的计算方法.
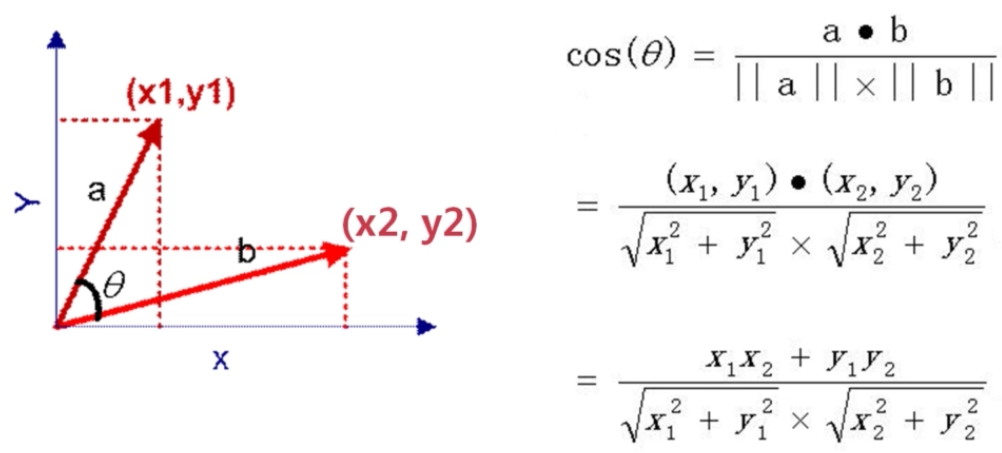 二维向量的余弦相似度
二维向量的余弦相似度计算两个用户的相似度,除了余弦相似度,还可以使用以下方法:
- 欧氏距离
- 曼哈顿距离
- 切比雪夫距离
- 皮尔森系数
- 杰夫德距离
用Python代码实现这个功能:
def distance(target_movies, movies):
"""
:param target_movies: 表示用户A有评分数据的电影
:param movies: 表示用户B有评分数据的电影
:return: 表示两个用户之间的距离
"""
# 求交集
union_len = len(set(target_movies) & set(movies))
if union_len == 0:
return 0.0
product = len(target_movies) * len(movies)
cosine = union_len / math.sqrt(product)
return cosine接下来我们遍历所有用户的电影评分记录,计算第1个用户与其他用户之间的相似度,并根据相似度进行排序.
def _get_top_n_users(csvpath, target_user_id, top_n):
frame = pd.read_csv(csvpath)
target_movies = frame[frame['UserID'] == target_user_id]['MovieID']
other_users_id = [i for i in set(frame['UserID']) if i != target_user_id]
other_movies = [frame[self.frame['UserID'] == i]['MovieID'] for i in other_users_id]
sim_list = [distance(target_movies, movies) for movies in other_movies]
sim_list = sorted(zip(other_users_id, sim_list), key=lambda x: x[1], reverse=True)
return sim_list[:top_n]我们指定target_user_id为1,top_n为10,即计算所有用户中与user_id为1的用户最相似的十个用户.
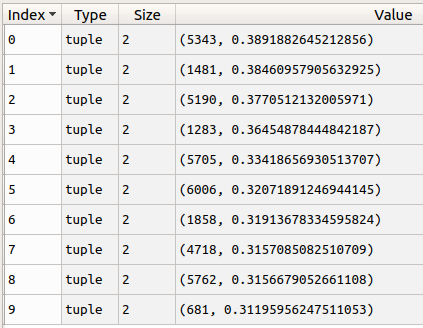 与user_id为1的用户最相似的十个用户.
与user_id为1的用户最相似的十个用户.可以看出,user_id=5343与user_id=1的相似度最高,达到了0.389.
让我们看一下user_id为1的用户的个人信息.用户的年龄与职业信息可以从这里下载:
字段说明可以从这里获得:
 user_id=1的个人信息
user_id=1的个人信息可以看出来,这个用户是一个年龄小于18岁的女孩,职业是:”K-12 student”(Age=1表示年龄小于18岁,Occupation=10表示职业为K-12 student),我们看一下推荐系统找出的10个相似度最高的用户的个人信息.
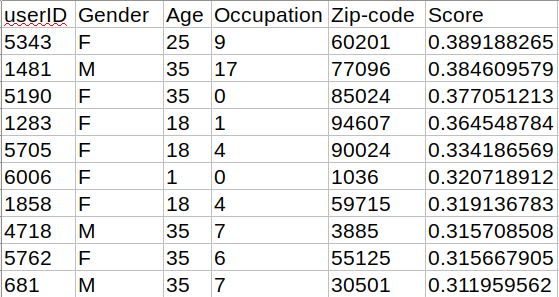
这里可以看出来,相似度最高的10个用户中,女性与男性的比例7:3,且低龄用户比例较高.可以看出用户的观影偏好与用户的性别,年龄存在一定的相关性.
本文使用了最简单的方法来分析用户之间的相关性,这里有很多地方可以优化,比如:
- 对过于热门的电影添加惩罚项,防止过于热门的电影对推荐系统造成影响
- 优化计算余弦相似度的过程,提高计算速度
参考资料:

发表回复