


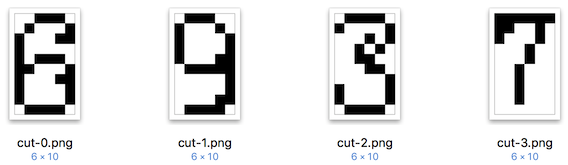
图像预处理的方法前面已经完成了,关键是用什么方法来进行图像比对呢?
一开始我想的很简单,直接对每张样本图片I1与测试图片I2相同坐标的像素进行逐一比对,计算I1与I2的相同坐标的像素相等的数目,最后求均值,得到10个分值,分数高的就是预测结果。
这个计算方法看起来可行,但是在实际使用的时候有一些问题
- 因为要遍历所有图片的所有像素,计算起来非常慢!
- 由于原始验证码图片添加了大量噪音,虽然做了降噪处理,但得到的同一类别图片之间还是存在较大差异。因此,如果用像素完全匹配的方法,容易有误判。
后来我找到了一个方法,先对样本图像进行编码转换。得到一个能体现图像特征的code,再将这些样本图像的code全部保存起来。这样下次要使用的时候,就不必每次都读一遍图片啦!
图片转code的方法我选择的hash转换,过程大致如下:
- 缩放:图片缩放为8*8
- 求平均值:计算灰度图所有像素的平均值
- 比较:像素值大于平均值记作1,相反记作0,总共64位
- 生成hash:将上述步骤生成的1和0按顺序组合起来既是图片的指纹(hash)。顺序不固定。但是比较时候必须是相同的顺序。
得到hash值后,将同一数字对于图片的hash值存在一个txt文件中,实际使用的时候,对预测图像进行上文相同的预处理操作,分割出4个图片后,再计算出4个预测图像的hash值,将测试图像的hash值与TXT文件中的hash进行比对,计算汉明距离,即两个64位的hash值有多少位是不一样的,不相同位数越少,图片越相似。
得到测试图像与每个样本图像hash值的汉明距离后,进行统计,平均,取预测值最大的样本图像标签为预测值。识别的速度也还不错,平均只需要0.3秒就可以完成一次识别。
这种识别的方法简单易操作,对简单的字母数字组合验证码非常有效,但是对图像预处理提出了更高的要求,而且不具备泛化性,碰到不同的验证码每次都需要单独编辑规则。

45